Save a Sliver of Flickr
Women making history.
Grandma’s 90th Birthday.
The local swim club.
Make an archive of Flickr’s most precious images, whatever that means to you.
Images from Flickr Commons
Women making history.
Grandma’s 90th Birthday.
The local swim club.
Make an archive of Flickr’s most precious images, whatever that means to you.
Images from Flickr Commons

Flickr is one of the largest cultural archives in human history with millions of new images, likes and comments added each day. The Flickr Foundation created Data Lifeboat, as user-friendly archiving solution to ensure memories on Flickr can be enjoyed by future generations, in easily browsable packages.
Login with your Flickr Account. Choose your photos. Write a README. Get a ZIP. It’s that simple. You can then navigate through your Flickr archive with any web browser. It’s like your own mini-website, no internet or database required.
You can also include other peoples photos, and we’ll help you get their consent.
Self contained
All you need is a web browser.
Long Lasting
Built with simple HTML and JS with no external dependencies. Lo-fi resilience at its finest.
Versatile
Whether it’s your family photos or your local motorcycle club, a Data Lifeboat fits.
Legible
Creator’s READMEs contain notes on permissions, licensing and overall context.
Likes, faves and comments- so many of our social interactions happening online. Saving an image is only capturing half the story. When archiving with Data Lifeboat, you can preserve Flickr images alongside their social context, whether it’s for personal use or to give future generations a look at what we were up to.
Grandma’s 90th birthday party. The day Obama came to your town. Or your favorite felines on Flickr!
Use Data Lifeboat to create a usable archive of whatever you’d like. Check out some Flickr archives made by our team.
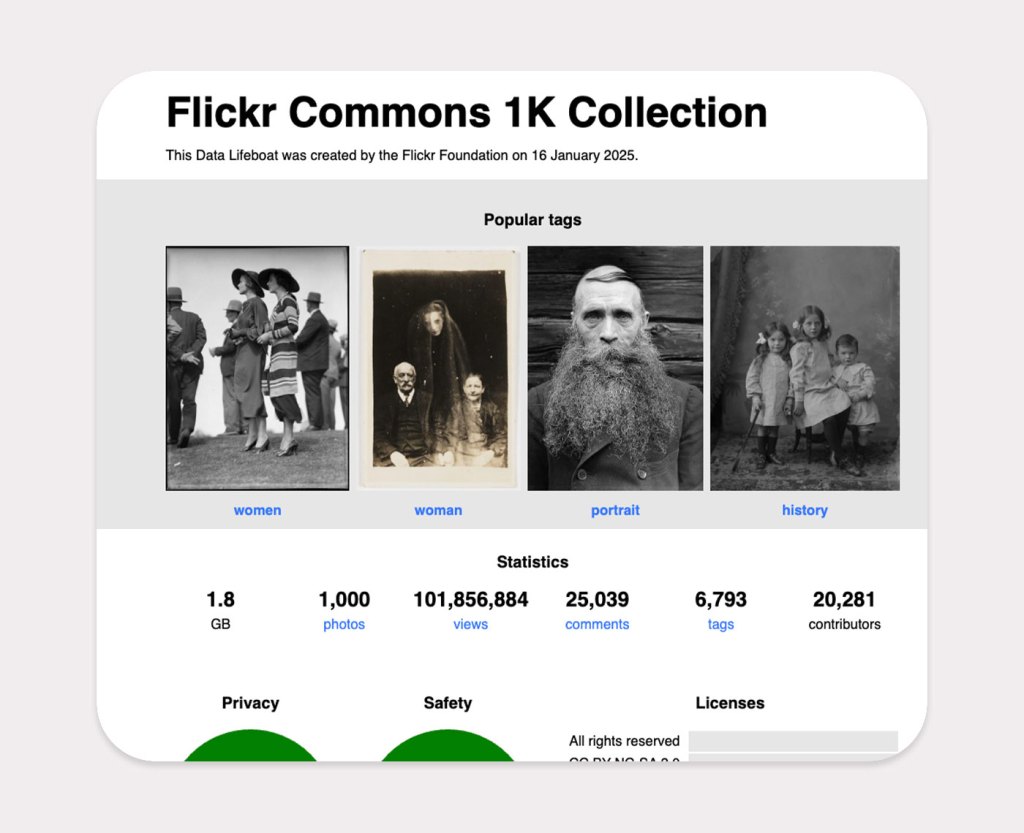
The Flickr Foundation produced this special collection for release in January 2025. It showcases some of the most popular photography across the groundbreaking Flickr Commons program. We hope you enjoy it!
The photos contained in this collection come to you with no known copyright restrictions. You are welcome to use them as you wish. Please consider giving credit to the cultural institutions who have shared these photos with us.
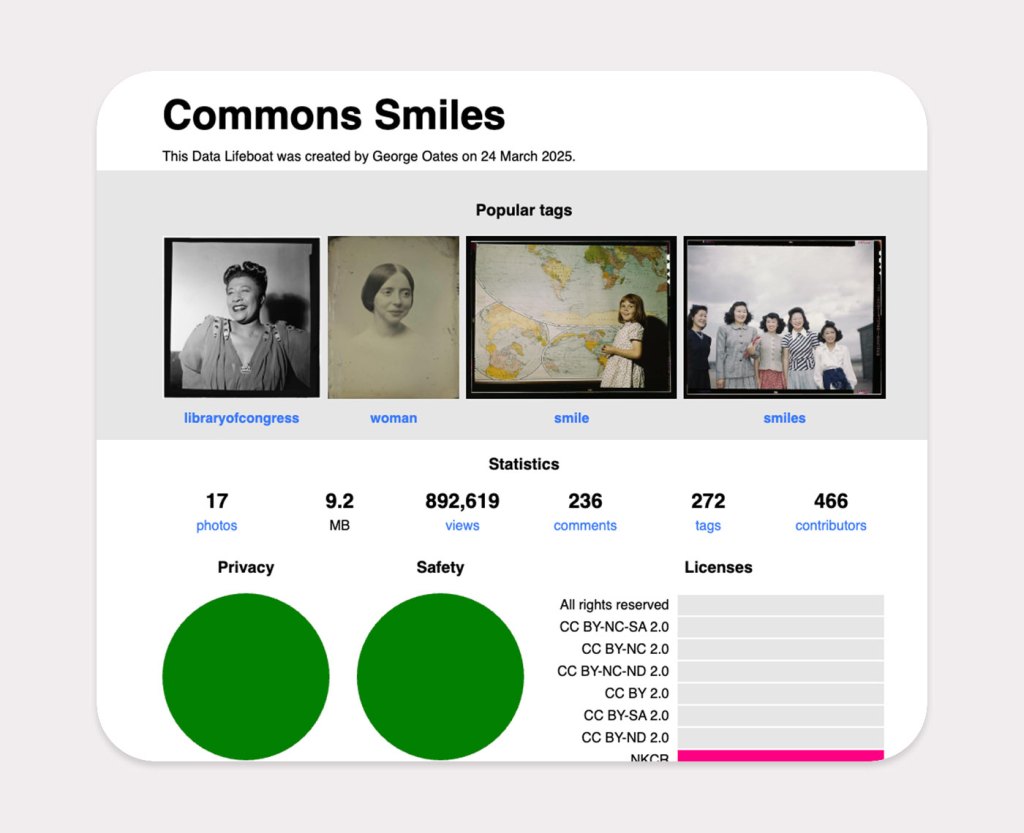
This is an example of a collection that emerged spontaneously from within the Commons photos, just by adding a tag.
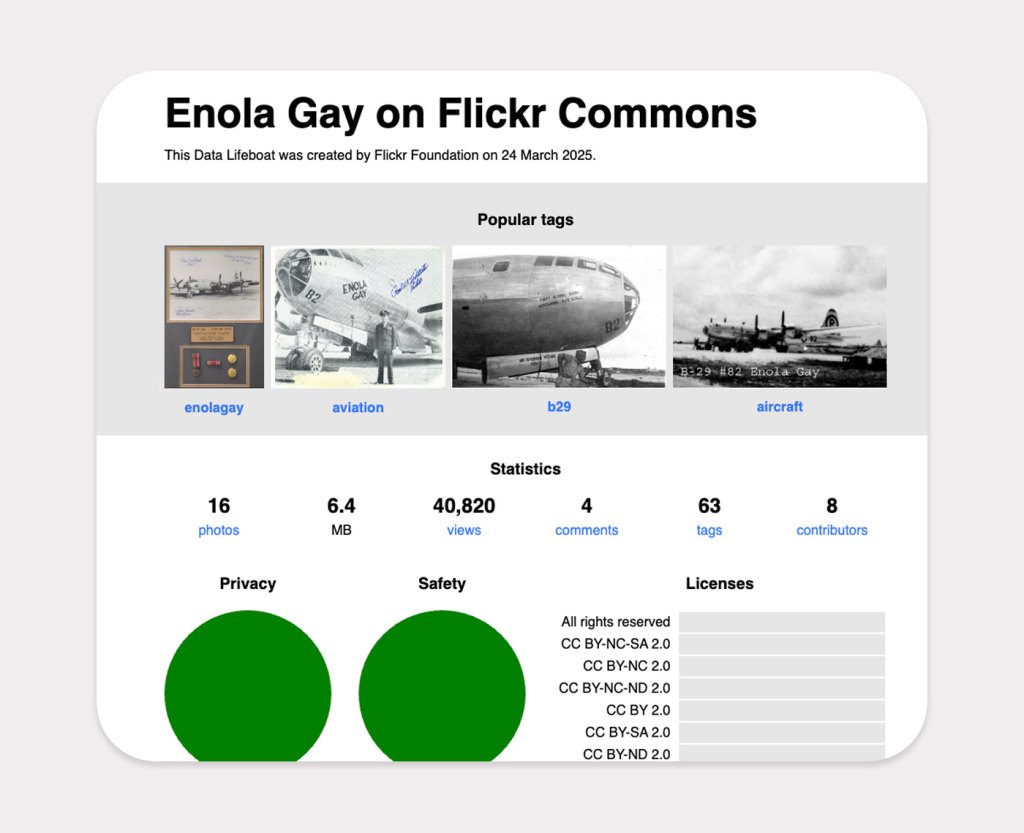
Photos of Enola Gay, gathered so we can preserve them. The photos contained in this collection come to you with no known copyright restrictions. You are welcome to use them as you wish. Please consider giving credit to the cultural institutions who have shared these photos with us.