In October and November, we held two Data Lifeboat workshops, funded by the Mellon Foundation. We had four days of detailed discussions about how Data Lifeboat should work, we talked about some of the big questions around ethics and care, and got a lot of useful input from our attendees.
As part of the workshops, we showed a demo of our current software, where we created and downloaded a prototype Data Lifeboat. This is an early prototype, with a lot of gaps and outstanding questions, but it was still very helpful to guide some of our conversations. Feedback from the workshops will influence what we are building, and we plan to release a public alpha next year.
We are sharing this work in progress as a snapshot of where we’ve got to. The prototype isn’t built for other people to use, but I can walk you through it with screenshots and explanations.
In this post, I’ll walk you through the creation workflow – the process of preparing a Data Lifeboat. In a follow-up post, I’ll show you what you get when you download a finished Data Lifeboat.
img { max-height: 70vh; display: block; margin: 0 auto; } h2 { margin-top: 1em; }Step 1: Sign in to Flickr
To create a Data Lifeboat, you have to sign in to your Flickr account:

This gives us an authenticated source of identity for who is creating each Data Lifeboat. This means each Data Lifeboat will reflect the social position of its creator in Flickr.com. For example, after you log in, your Data Lifeboat could contain photos shared with you by friends and family, where those photos would not be accessible to other Flickr members who aren’t part of the same social graph.
Step 2: Choose the photos you want to save
To choose photos, you enter a URL that points to photos on Flickr.com:

In the prototype, we can only accept a single URL, either a Gallery, Album, or Photostream for now. This is good enough for prototyping, but we know we’ll need something more flexible later – for example, we might allow you to enter multiple URLs, and then we’d get photos from all of them.
Step 3: See a summary of the photos you’d be downloading
Once you’ve given us a URL, we fetch the first page of photos and show you a summary. This includes things like:
- How many photos are there?
- How many photos are public, semi-public, or private?
- What license are the photos using?
- What’s the safety level of the photos?
- Have the owners disabled downloads for any of these photos?

Each of these controls affects what we are permitted to put in a Data Lifeboat, and the answers will be different for different people. Somebody creating their family archive may want all the photos, whereas somebody creating a Data Lifeboat for a museum might only want photos which are publicly visible and openly licensed.
We want Data Lifeboat creators to make informed decisions about what goes in their Data Lifeboat, and we believe we can do better than showing them a series of toggle switches. The current design of this screen is to give us a sense of how these controls are used in practice. It exposes the raw mechanics of Flickr.com, and relies on a detailed understanding of how Flickr.com works. We know this won’t be the final design. We might, for example, build an interface that asks people where they intend to store the Data Lifeboat, and use that to inform which photos we include. This is still speculative, and we have a lot of ideas we haven’t tried yet.
The prototype only saves public, permissively-licensed photos, because we’re still working out the details of how we handle licensed and private photos.
Step 4: Write a README
This is a vital step – it’s where people give us more context. A single Data Lifeboat can only contain a sliver of Flickr, so we want to give the creator the opportunity to describe why they made this selection, and also to include any warnings about sensitive content so it’s easier to use the archive with care in future.
Tori will be writing up what happened at the workshops around how we could design this particular interface to encourage creators to think carefully here.

We like the idea of introducing ‘positive friction’ to this process, supporting people to write constructive and narrative notes to the future about why this particular sliver is important to keep.
Step 5: Agree to policies
When you create a Data Lifeboat, you need to agree to certain conditions around responsible use of the photos you’re downloading:

The “policies” in the current prototype are obviously placeholders. We know we will need to impose certain conditions, but we don’t know what they are yet.
One idea we’re developing is that these policies might adapt dynamically based on the contents of the Data Lifeboat. If you’re creating a Data Lifeboat that only contains your own public photos, that’s very different from one that contains private photos uploaded by other people.
Step 6: One moment please…
Creating or “baking” a Data Lifeboat can take a while – we need to download all the photos, their associated metadata, and construct a Data Lifeboat package.
In the prototype we show you a holding page:

We imagine that in the future, we’d email you a notification when the Data Lifeboat has finished baking.
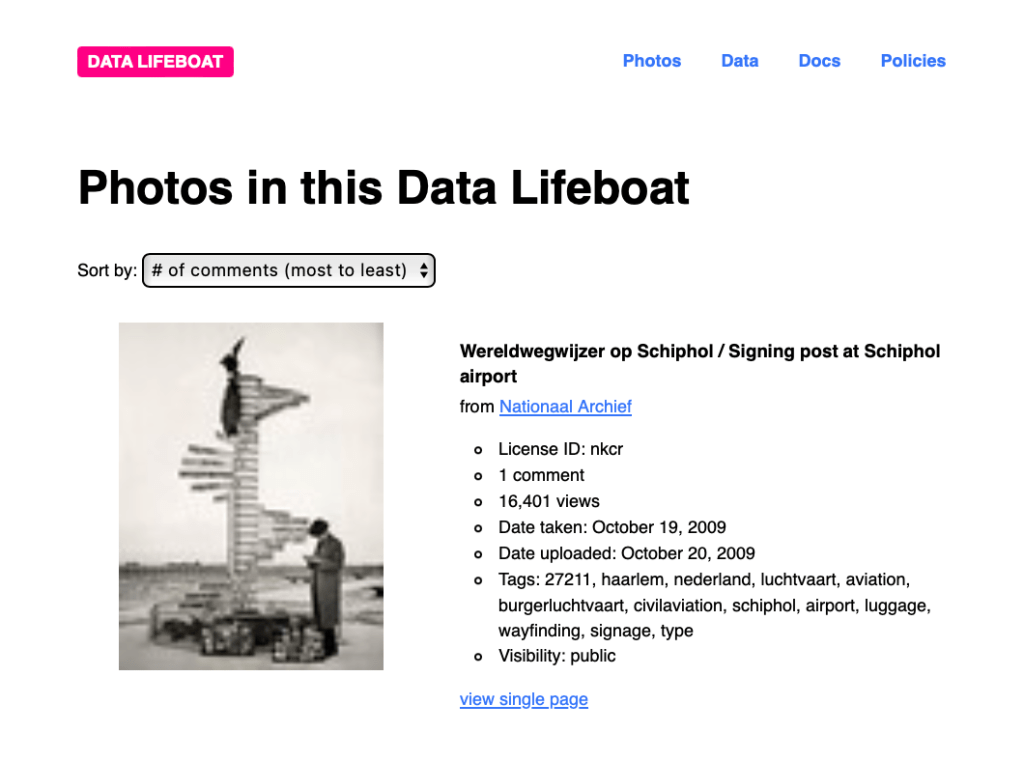
Step 7: Download the Data Lifeboat
We have a page where you can download your Data Lifeboat:

Here you see a list of all the Data Lifeboats that we’ve been prototyping, because we wanted people to share their ideas for Data Lifeboats at our co-design workshops. In the real tool, you’ll only be able to see and download Data Lifeboats that you created.
What’s next?
We still have plenty to get on with, but you can see the broad outline of where we’re going, and it’s been really helpful to have an end-to-end tool that shows the whole Data Lifeboat creation process.
Come back next week, and I’ll show you what you get inside the Data Lifeboat when you download it!