Blog











Our new bot improves metadata for Flickr photos on Wikimedia Commons, and makes it easier to find out which photos have been copied across.
More questions than answers, and that's a good thing.
We’ve made a library that knows how to read lots of different forms of Flickr.com URL.
We're thrilled to join the fold of organizations connected with and supported by the Mellon Foundation.
First of three installments from Eryk Salvaggio as part of his research on generated imagery and Flickr.
A report on archival strategies by Ashley Kelleher Skjøtt.
Prakash Krishnan (he/him) is an artist-researcher and cultural worker, and joins us on a research fellowship in 2024.
One of the Flickr Foundation's research partners, based in California.
Jenn reflects on her six months working with the Flickr Foundation crew.
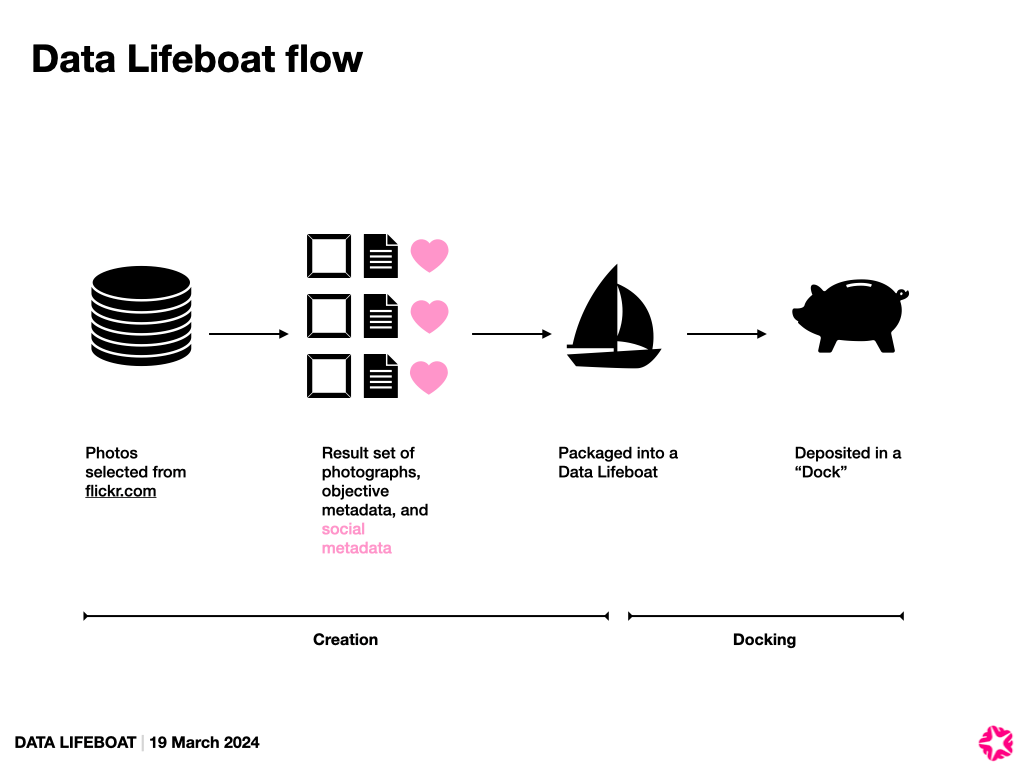
What are the different systems and pieces involved in creating a Data Lifeboat?
Let’s dive under the hood and find out how the new Commons Explorer works.
Learning about physical lifeboat design, starting legal framework with C.A.R.E.
Browse around the wonderful Flickr Commons collection all in one place!
Looking closer at a passing piece of pop culture.
Digital photography is worth collecting...but how?
| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |