Data Lifeboat: NEH Grant Update 1
By Ewa SpohnAnd we’re off! Thanks to the Digital Humanities Advancement Grant we were awarded by the National Endowment for the Humanities, our work on the Data Lifeboat has started, in our Content Mobility program. We’ll be posting an update for you each month.

Excellent Lifeboat-related game and book brought in by Alex for our Kick-off
What’s a Data Lifeboat?
A quick recap for those not familiar with the concept, from our grant narrative:
“A Data Lifeboat is an archival piece of Flickr, not all of the 50 billion images and their metadata. For example, a Lifeboat might contain all the photos tagged with “sunflower” or all the Recipes to Share group submissions. Whatever facet of the data you can think of, you could generate a Data Lifeboat for it. We envision an archival sliver richer than a mere folder of JPGs: one where you can navigate the content to explore and understand its networked context. Even better, an archival sliver that is updated if things change at flickr.com. Our goals with this project are to create several rough prototypes of the software, develop a reasonably detailed understanding of the main technical challenges, prepare a survey of critical ongoing legal issues, and establish a robust design direction for further product development.”
This idea was born from two challenges: 1) Flickr contains a multitude of shared histories, and is owned and controlled by a corporation which could decide to close the service, which—as we’ve seen in the past—can result in the destruction of cultural heritage, and 2) the Flickr archive is huge and, in its current form, impossible for any one archival institution to take on.
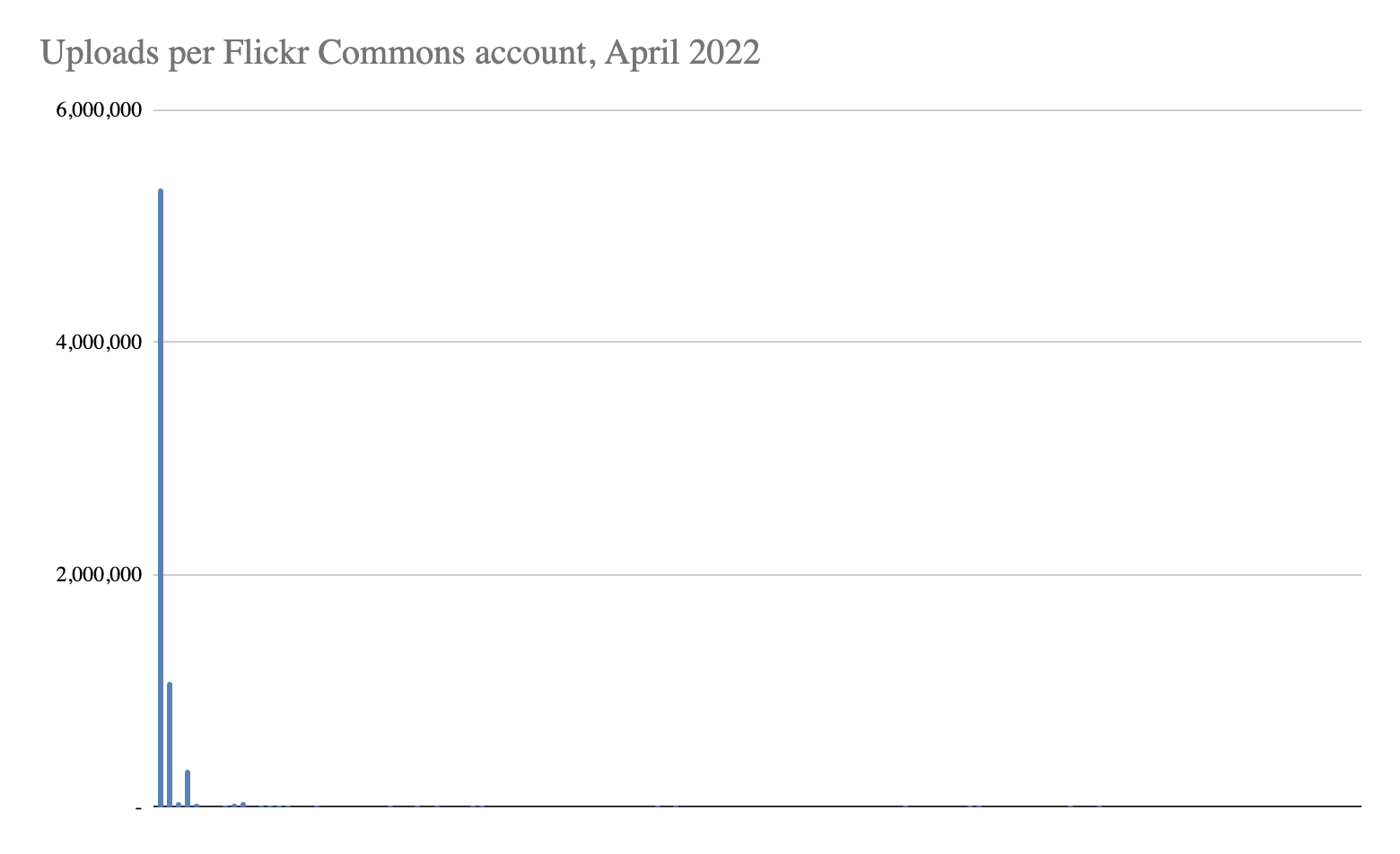
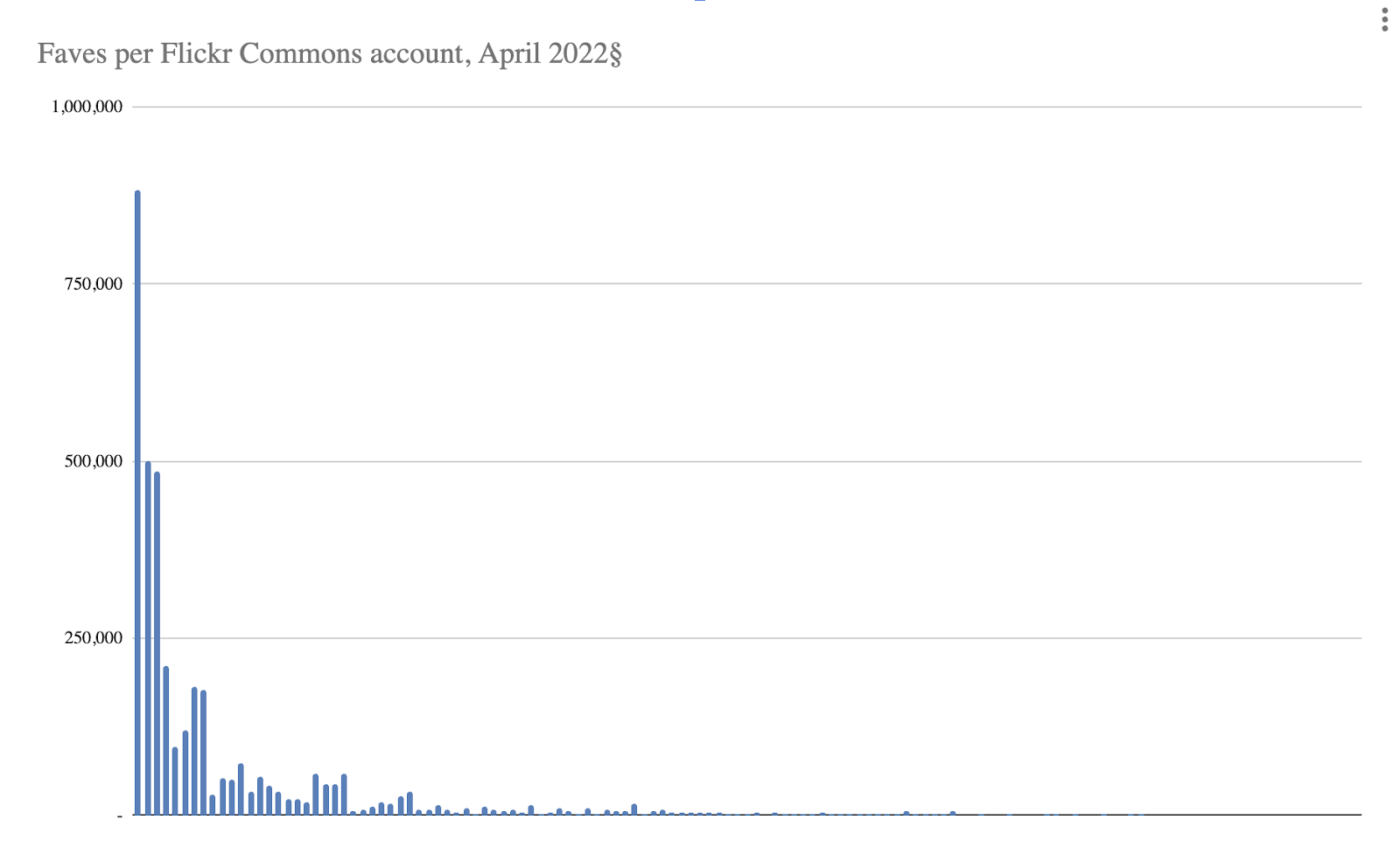
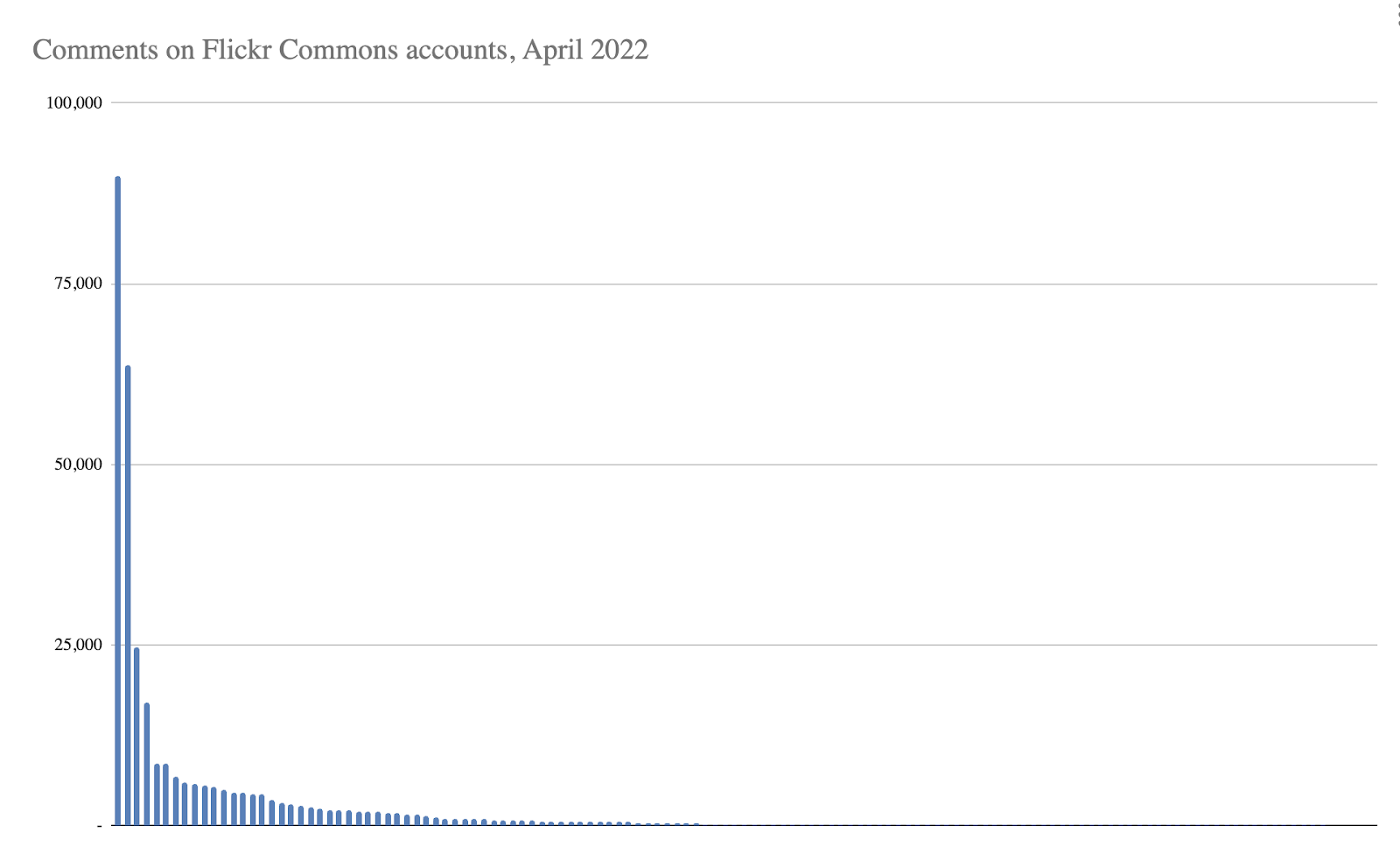
Flickr’s 50 billion or so photos reflect our diverse heritage, traditions, and history back to us in a unique way. The collection is also born digital, a massive advantage over conventional archives, because the photographers usually describe their pictures themselves as they publish. The pictures are also enriched by the network of social activity that surrounds them, which – again – is unique to the Flickrverse. Finally, this kind of volume is astonishing: Flickr and other platforms like it are orders of magnitude larger than our biggest cultural collections to date.
At the Foundation, we believe we must begin to treat this collection as we would our ‘traditional’ great libraries, archives, and collections. Time is of the essence: the commercial platforms that host these kinds of huge collections can (and do) disappear, effectively sinking our heritage along with them. Our hope is that a Data Lifeboat will carry Flickr images away from the possibility of a sinking ship unscathed. Our future plans include developing the idea of a “dock” in a “safe harbour” – somewhere specific for the Data Lifeboat to land and be preserved.
The scope of the grant
We’re using the NEH grant to create two identical prototype Data Lifeboats containing a selection of the Flickr Commons. This will (hopefully) be a richer archival format that allows for the exploration of content within its networked context, and one that can be updated when changes are introduced in Flickr.com. Importantly, we want to place these two Lifeboats in two different places, a proxy for our developing goal of “safe harbours” for them.
This phase of the project, making a demonstrable prototype, or prototypes, is scheduled to end mid-year.
Our crew
It’s an exciting and completely new thing, and working on it is a multidisciplinary team drawn from both the Flickr Foundation and our Flickr Commons members and advisors:
- George Oates, Project Director, who provides strategic and design input, and financial oversight
- Alex Chan, Tech Lead, who is developing the core of our prototypes
- Jessamyn West, Community Manager, who leads our communication with the Flickr Commons collaborators, the project advisors, as well as broader audiences
- Ewa Spohn, Project Manager, who ensures the team sticks to the plan. And budget
We’re excited to engage some of our Flickr Commons members directly for the first time, too. The Flickr Foundation team will be joined by staff from three of our member institutions:
- Dr Mia Ridge, Digital Curator at the British Library
- Alan Renga, Digital Archivist at the San Diego Air & Space Museum
- Mary Grace Kosta, Congregational Archivist at the Congregation of the Sisters of St. Joseph in Canada
And finally, our advisors, who bring a wide range of experience and knowledge and will help us make sure we build stuff for the long term:
- Trevor Owens, Director of Digital Services, Library of Congress
- Neil Jefferies, Head of Innovation at the Bodleian Libraries, University of Oxford
- Ilya Kremer, Lead Developer at Webrecorder
- Jed Sundwall, Executive Director at Radiant Earth
- Dietrich Ayala, Advisor at the Filecoin Foundation
Kick-off? Done.
We’re about to have our first all-hands meeting, although in late January we took advantage of Dietrich’s short visit to London to hold our first face-to-face workshop.

Jenn, Ewa, George, Alex, Stef, and Dietrich (the photographer) at our kick-off at HQ
Over coffee and sugary snacks, we spent two days exploring decentralized storage and how it could be applied to archiving digital content, and thinking through a possible schema for the data in a data lifeboat.
Emerging questions
Many, many (#many) questions arose (for which we currently have no answers), for example:
- Is a Data Lifeboat launched in response to an emergency or as part of regular housekeeping?
- What must a Data Lifeboat contain? Could it initially just be a manifest and the images (which are large and expensive to process) are added later?
- Who decides what is in (and out) of a Data Lifeboat and to what extent should it feel like an active selection?
- Where are the ‘edges’ of the network surrounding a Flickr photo, and what is a holistic archive?
- What existing digital asset management formats could (should) a Data Lifeboat be consistent with for it to be ‘docked’ successfully?
We were also very pleasantly surprised by the power of our lifeboat metaphor and how far we could stretch it to help coordinate our thinking! And thanks again to Dietrich for sharing time with us to crack the project open.
Next steps
Next up is our first all-hands meeting to bring the whole project team up to speed with the plan. That’ll be followed by a deep dive review of digital asset management systems in cultural institutions and a survey of the legal rocks that a Data Lifeboat may encounter. We think that will give us enough to allow us to define some high level requirements for the prototypes so that the development proper can start towards the end of the month.
Somewhere among all that we’re also planning a team expedition to a lifeboat museum to learn more about how lifeboats work in the physical world, but more about that in another blog post…
This work is supported by the National Endowment for the Humanities.